

Google Cloud Functions와 Puppeteer을 활용해서 크롤링하는 방법을 익혀보고 더 나아가 Google Cloud Scheduler를 활용해서 크롤링 자동화까지 구현해보도록 하겠습니다. 해당 포스팅에서는 Google Cloud Functions, Puppeteer 그리고 Google Cloud Scheduler를 기본적으로 숙지하고 있다는 가정하에 진행하도록 하겠습니다. 간략하게 짚고 넘어가면 아래와 같습니다.
Google Cloud Functions
Google Cloud Functions는 클라우드 서비스를 빌드 및 연결하기 위한 서버리스 실행 환경입니다. Cloud Functions를 사용하면 클라우드 인프라와 서비스에서 발생하는 이벤트에 연결되는 단일 목적의 간단한 함수를 작성할 수 있습니다.
Cloud Functions 개요 | Cloud Functions 문서 | Google Cloud
Google Cloud Functions란 무엇인가요? Google Cloud Functions는 클라우드 서비스를 빌드 및 연결하기 위한 서버리스 실행 환경입니다. Cloud Functions를 사용하면 클라우드 인프라와 서비스에서 발생하는 이벤트에 연결되는 단일 목적의 간단한 함수를 작성할 수 있습니다. 함수는 감시 중인 이벤트 발생 시에 트리거됩니다. 코드는 완전 관리형 환경에서 실행되므로, 인프라를 프로비저닝하거나 서버를 관리할 필요가 없습니다.
cloud.google.com
Puppeteer
Puppeteer는 구글에서 만든 Headless Chrome Node API입니다. 여기서 Headless란 일반적인 CLI 환경에서 브라우저가 사용자의 눈에 보여지지 않고, 백그라운드에서 작동하는 것을 의미합니다. (GUI가 없는 브라우저)
Puppeteer은 Headless 모드나 headful 모드에서 웹 페이지를 자동화, 테스트 및 스크랩 하는 데 매우 유용하고 쉬운 도구입니다.
puppeteer
A high-level API to control headless Chrome over the DevTools Protocol
www.npmjs.com
Google Cloud Scheduler
예약작업을 도와주는 Cloud Scheduler는 엔터프라이즈 수준의 완전 관리형 크론 작업 스케줄러로서 일괄 및 빅데이터 작업, 클라우드 인프라 작업 등을 비롯한 거의 모든 작업의 예약을 돕습니다. 장애 발생 시 재시도를 포함하여 모든 작업을 자동화할 수 있으므로 수작업이나 사용자의 개입 필요성을 줄일 수 있습니다. 또한 Cloud Scheduler가 단일 창구의 기능을 수행함에 따라 한 곳에서 모든 자동화 작업을 관리할 수 있습니다.
기본 환경구성
yarn init -y// install puppeteer
yarn add puppeteerGoogle Cloud Functions를 로컬에서 테스트하기 위한 패키지와 Google Cloud Storage에 접근하기 위해 필요한 라이브러리를 설치합니다.
yarn add @google-cloud/functions-framework @google-cloud/storage
package.json의 내용은 아래와 같습니다.
{
"name": "gcf-crawler",
"version": "1.0.0",
"main": "index.js",
"license": "MIT",
"dependencies": {
"@google-cloud/functions-framework": "^1.4.0",
"@google-cloud/storage": "^4.3.1",
"puppeteer": "^2.1.1"
}
}
gcloud 초기화
gcloud cli를 활용하기 위해서 gcloud 명령어를 설정해야합니다. 설정하는 방법은 아래 링크에서 확인 가능합니다. gcloud 명령어를 아직 추가 안하신 분들은 아래 링크로 가셔서 설정하시기 바랍니다.
GCP(Google Cloud Platform) App Engine에 Nuxt(Vue SSR) Application 배포하는 방법
GCP(Google Cloud Platform) App Engine에 Nuxt(Vue SSR) Application 배포하는 방법(Deploy Vue+Nuxt app to GCP Engine)
GCP App Engine에 Nuxt Application을 배포하는 방법에 대해서 소개하도록 하겠습니다. AWS에 익숙하신 분들은 GCP App Engine과 AWS Elastic Beanstalk과 동일하다고 보시면 됩니다. 해당 포스팅은 GCP 회원가입..
webruden.tistory.com
GCP(Google Cloud Platform) App Engine에 Next(React SSR) Application 배포하는 방법
GCP(Google Cloud Platform) App Engine에 Next(React SSR) Application 배포하는 방법(Deploy React+Next app to GCP Engine)
GCP App Engine에 Next Application을 배포하는 방법에 대해서 소개하도록 하겠습니다. AWS에 익숙하신 분들은 GCP App Engine과 AWS Elastic Beanstalk과 동일하다고 보시면 됩니다. 해당 포스팅은 GCP 회원가입..
webruden.tistory.com
package.json에 아래의 scripts를 추가합니다.
"scripts": {
"start": "functions-framework --target=example",
"deploy": "gcloud functions deploy example --trigger-http --runtime nodejs10 --memory 1024MB --region asia-northeast1"
},start에 functions-framework은 위에서 설치한 @google-cloud/functions-framework 라이브러리의 명령어로써 로컬에서 Cloud Functions를 테스트하기 위해 추가했습니다. --target 옵션은 특정 이름을 가진 함수를 실행시키는 옵션입니다. ex) --target=example, example이라는 클라우드 함수를 실행한다는 의미가 되겠습니다.
deploy는
gcloud functions deploy example - example 클라우드 함수를 배포하고
--trigger-http - http 함수 사용
--runtime nodejs10 - nodejs 10버전 사용
--memory 1024MB - 메모리는 1024로 올리고
--region - 리전은 asia-northeast1(도쿄)를 사용
이러한 옵션을 지정해주고 실행해줍니다.
index.js
const puppeteer = require("puppeteer");
exports.example = (req, res) => {
try {
res.status(200).send("함수 실행 완료");
// .send(`${json.updatedDate}, 데이터를 성공적으로 저장했습니다.`);
} catch (err) {
res.status(500).send(err.message);
}
};
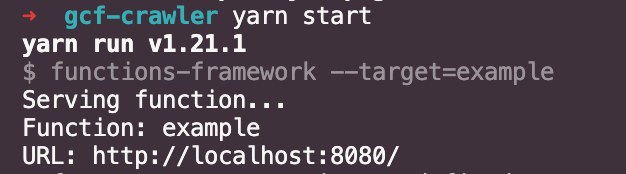
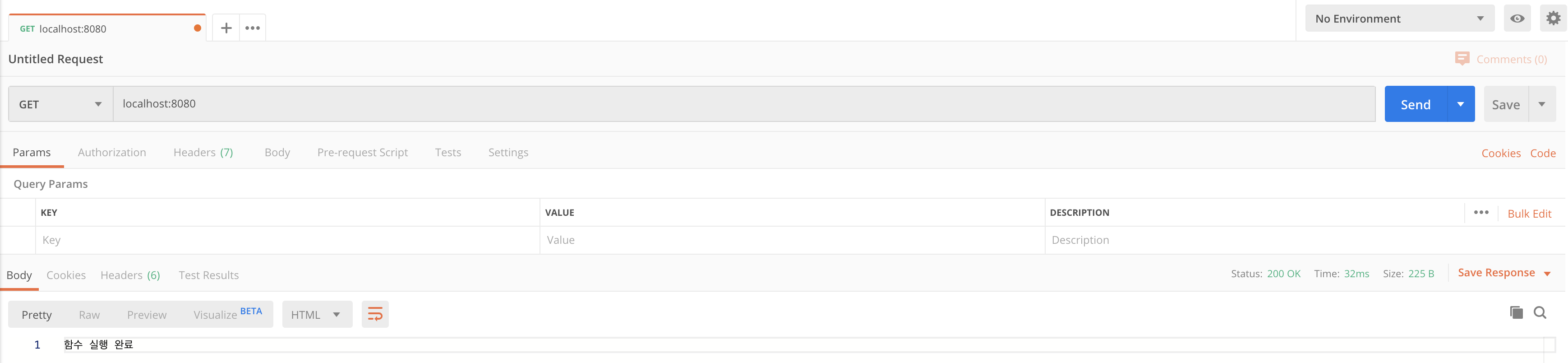
yarn start스크립트를 실행한 후 포스트맨으로 결과를 확인해본 결과 정상적으로 상태코드 200 그리고 함수 실행 완료라는 스트링이 리턴값으로 내려오고 있음을 확인할 수 있습니다.
그럼 이제 puppeteer를 추가하겠습니다. puppeteer의 기본 옵션을 세팅하고 연결할 준비를 합니다.
연습으로 네이버 메인페이지의 body 컨텐츠를 가져오도록 하겠습니다.
const puppeteer = require("puppeteer");
const PUPPETEER_OPTIONS = {
// headless: true,
args: ["--disable-setuid-sandbox", "--no-sandbox"]
};
const openConnection = async () => {
const browser = await puppeteer.launch(PUPPETEER_OPTIONS);
const page = await browser.newPage();
return { browser, page };
};
const closeConnection = async (page, browser) => {
page && (await page.close());
browser && (await browser.close());
};
const url = "https://www.naver.com";
exports.scrapingExample = async (req, res) => {
let { browser, page } = await openConnection();
try {
await page.goto(url, { waitUntil: "load" });
const data = await page.evaluate(() => {
return document.querySelector("body").innerHTML;
});
res.status(200).send(data);
} catch (err) {
res.status(500).send(err.message);
} finally {
closeConnection(page, browser);
}
};
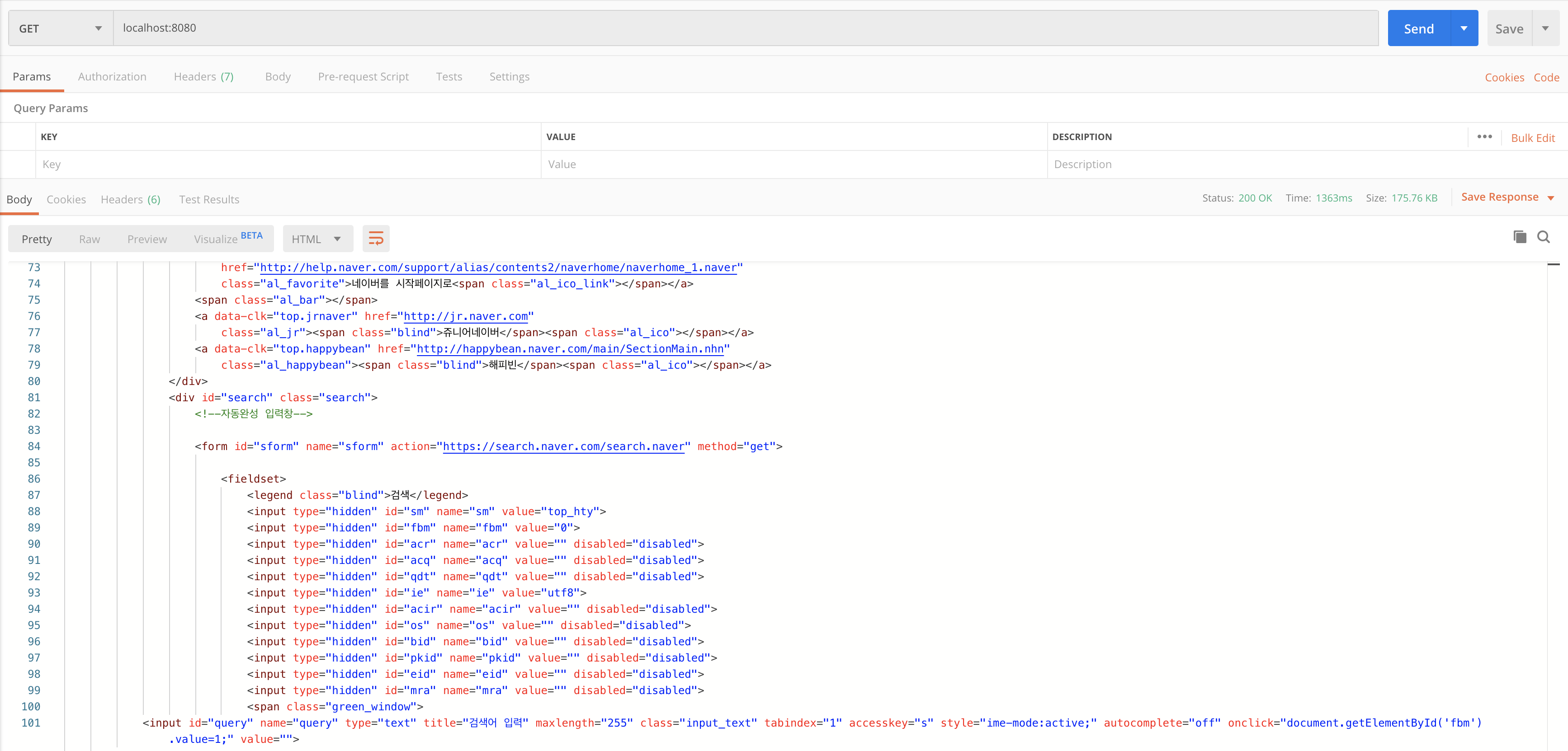
Google Cloud Storage 저장해보자
자 그러면 작업하기 위한 준비는 모두 끝났습니다. 원하는 데이터를 원하는 페이지의 HTML 구조에 맞춰서 데이터를 크롤링하고 가져온 데이터를 JSON 포맷으로 만들어서 Google Cloud Storage에 저장하면 됩니다.
사전에 Google Cloud Storage 라이브러리를 설치했습니다. 아직 설치 안하셨으면 다시 위로 돌아가서 설치하시기 바랍니다.
Google Cloud Storage를 정상적으로 사용하려면 GCP key가 필요합니다.
서비스 계정 키 만들기 및 관리 | Cloud IAM 문서 | Google Cloud
이 페이지에서는 Google Cloud Console, gcloud 명령줄 도구 또는 Cloud Identity and Access Management API를 사용하거나 Google Cloud 클라이언트 라이브러리 중 하나를 사용하여 서비스 계정 키를 만들고 관리하는 방법을 설명합니다. 이 가이드의 기본 요건 필수 권한 사용자가 서비스 계정 키를 관리할 수 있도록 서비스 계정 키 관리자 역할(roles/iam.serviceAccountKeyAdmin)을
cloud.google.com
형식은 아래와 같습니다.
{
"type": "",
"project_id": "",
"private_key_id": "",
"private_key": "",
"client_email": "",
"client_id": "",
"auth_uri": "",
"token_uri": "",
"auth_provider_x509_cert_url": "",
"client_x509_cert_url": ""
}
Google Cloud Storage를 좀 더 편하게 사용하기 위해 utils/storage에 필요한 로직을 구현했습니다.
yarn add os fs dotenv app-root-pathconst { Storage } = require('@google-cloud/storage')
const rootPath = require('app-root-path');
const path = require('path');
const os = require('os');
const fs = require('fs');
const dotenv = require('dotenv')
const { getTimestamp, getUpdatedDate, makeJSON } = require(`~utils`);
dotenv.config()
class Store {
constructor() {
this.BUCKET_NAME = '버킷이름';
this.storage = new Storage({
"projectId": '프로젝트 ID',
keyFilename: `${rootPath}/key.json`
})
}
upload(file, options) {
const mergedOptions = Object.assign({}, {
gzip: true,
public: true,
metadata: {
cacheControl: 'public, max-age=600, must-revalidate', // 10 minutes cache
},
}, options)
this.storage.bucket(this.BUCKET_NAME).upload(file, mergedOptions)
}
writeFileSync(file, json) {
fs.writeFileSync(file, JSON.stringify(json));
}
getTempFileName(fileName) {
return path.join(os.tmpdir(), fileName);
}
}
module.exports = {
storage: new Store(),
getTimestamp,
getUpdatedDate,
makeJSON
}
데이터 저장을 위한 버킷이름과 프로젝트 ID는 아래와 같이 확인할 수 있습니다.

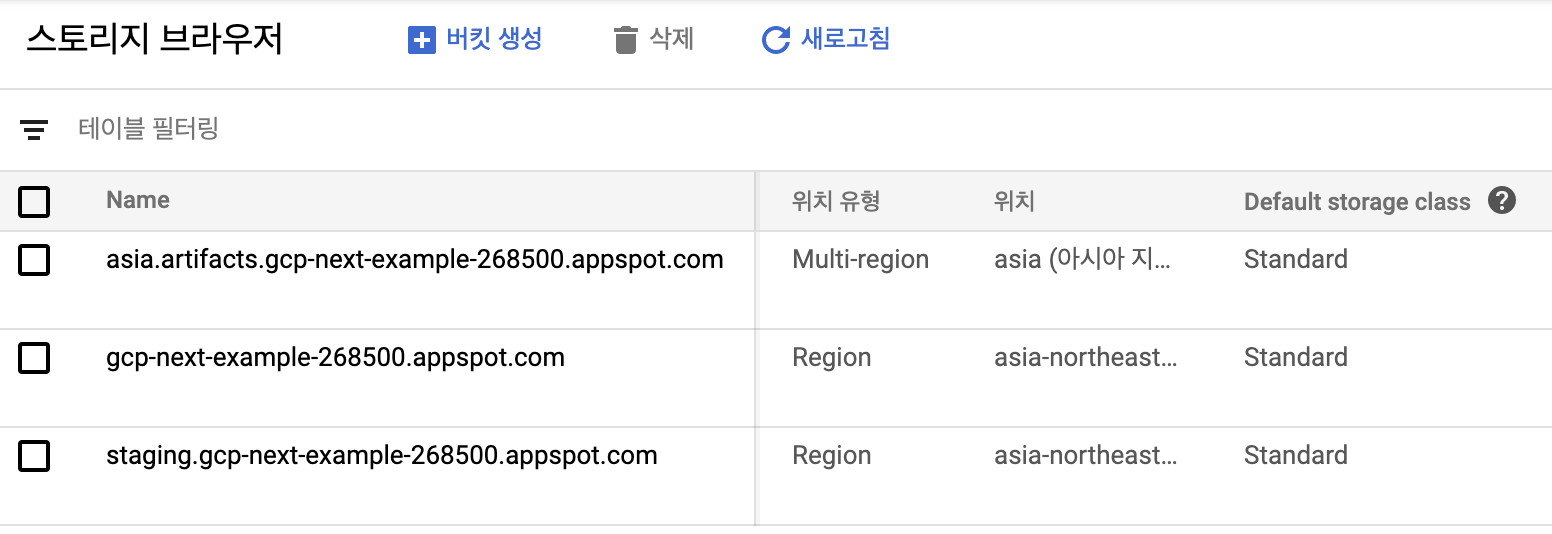
아래와 같이 storage를 import하고 크롤링한 data를 json형식으로 만들어서 storage에 업로드해줍니다.
const { storage, makeJSON } = require(`./utils/storage`); // 추가
exports.scrapingExample = async (req, res) => {
let { browser, page } = await openConnection();
try {
await page.goto(url, { waitUntil: "load" });
const data = await page.evaluate(() => {
return document.querySelector("body").innerHTML;
});
const json = makeJSON({ data });
const file = storage.getTempFileName("data.json");
storage.writeFileSync(file, json);
storage.upload(file);
res.status(200).send(data);
} catch (err) {
res.status(500).send(err.message);
} finally {
// closeConnection(page, browser);
}
};
정상적으로 스토리지에 업로드가 된 것을 확인했으니 이제 함수를 실제 배포해봅니다. 배포는 굉장히 간단합니다.
yarn deploy배포가 완료되었습니다. 그러면 실제로 잘 올라갔나 한번 확인해볼까요?
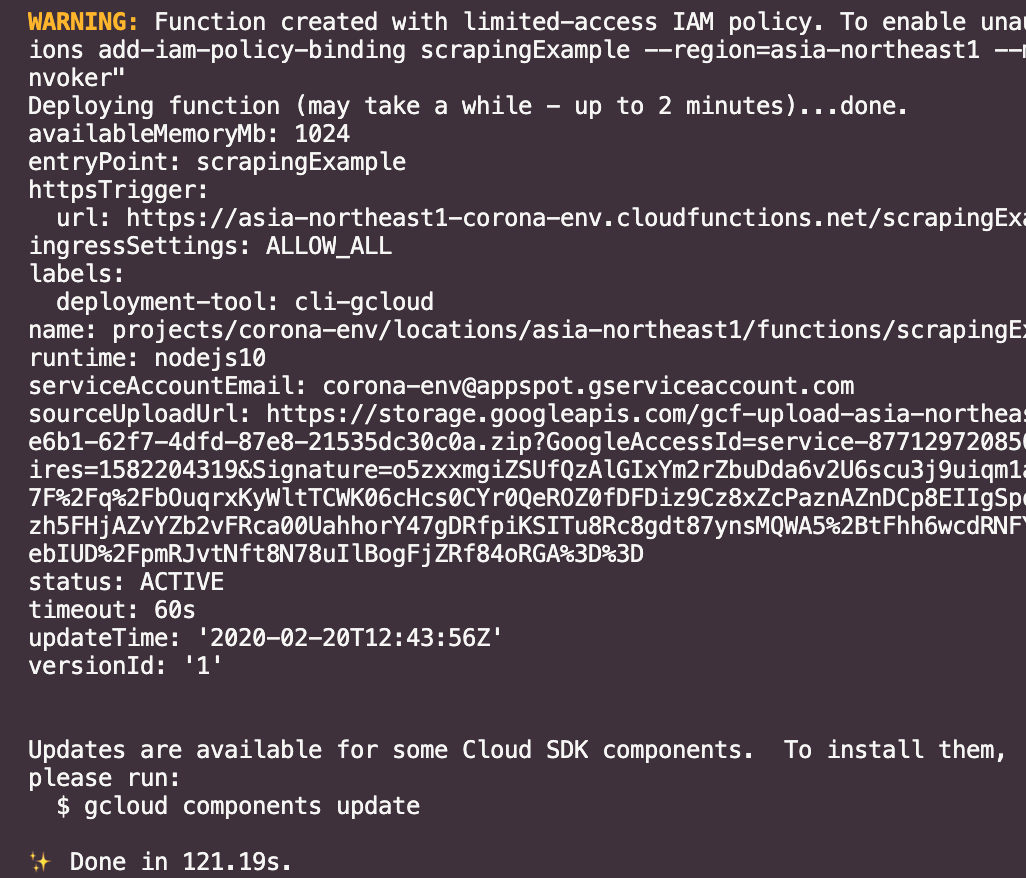

클라우드 함수 목록을 보니 함수가 잘 올라가 있음을 확인할 수 있습니다. 실제 정상적으로 동작하나 한번 테스트도 해봅시다.
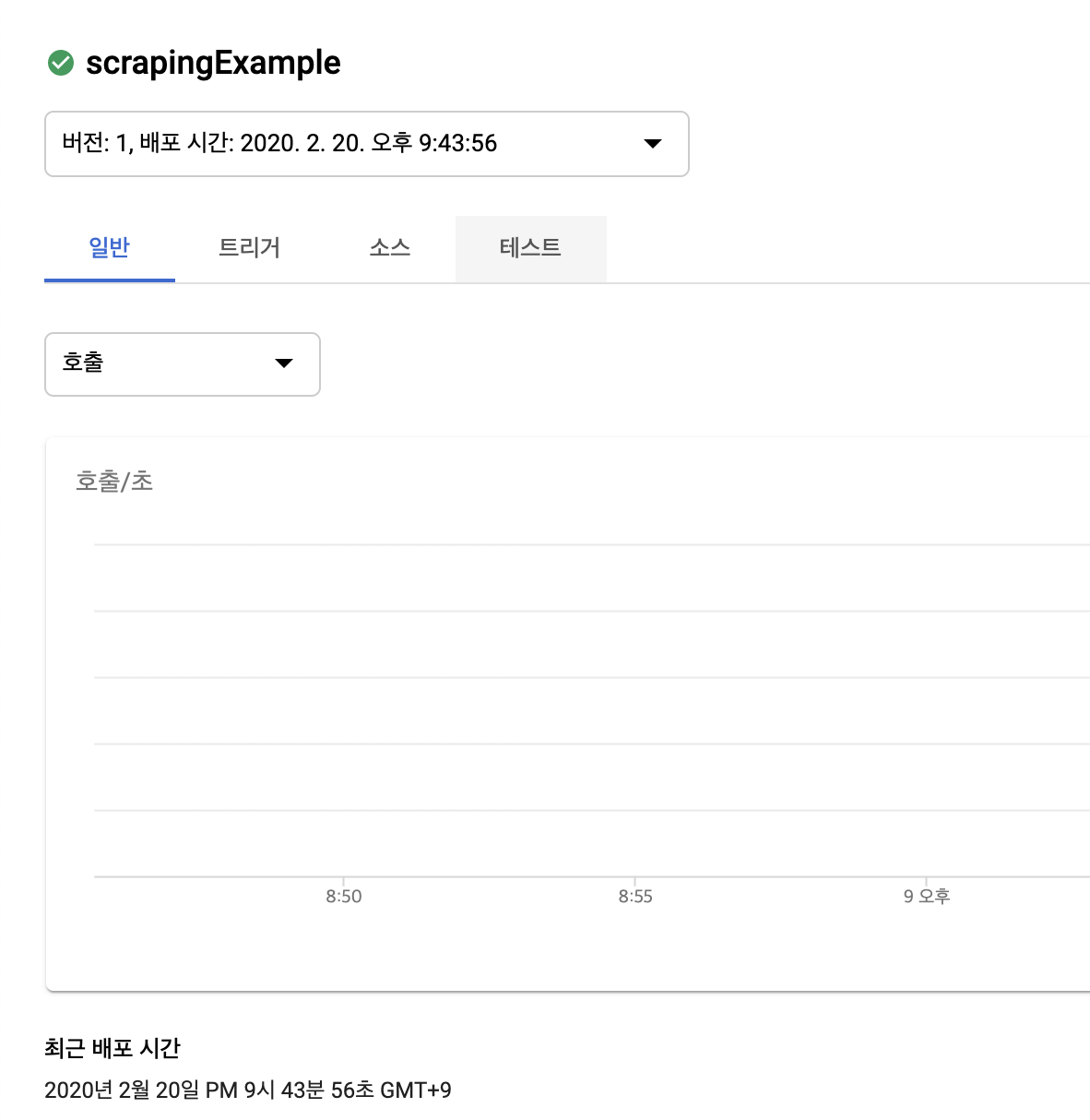
함수 상세 목록을 들어가서 테스트탭 그리고 함수 테스트를 실행한 후 조금 기다리면 정상적으로 함수가 실행이 되고 해당하는 출력 결과를 보여줍니다. 정상적으로 잘 실행이 되었네요.

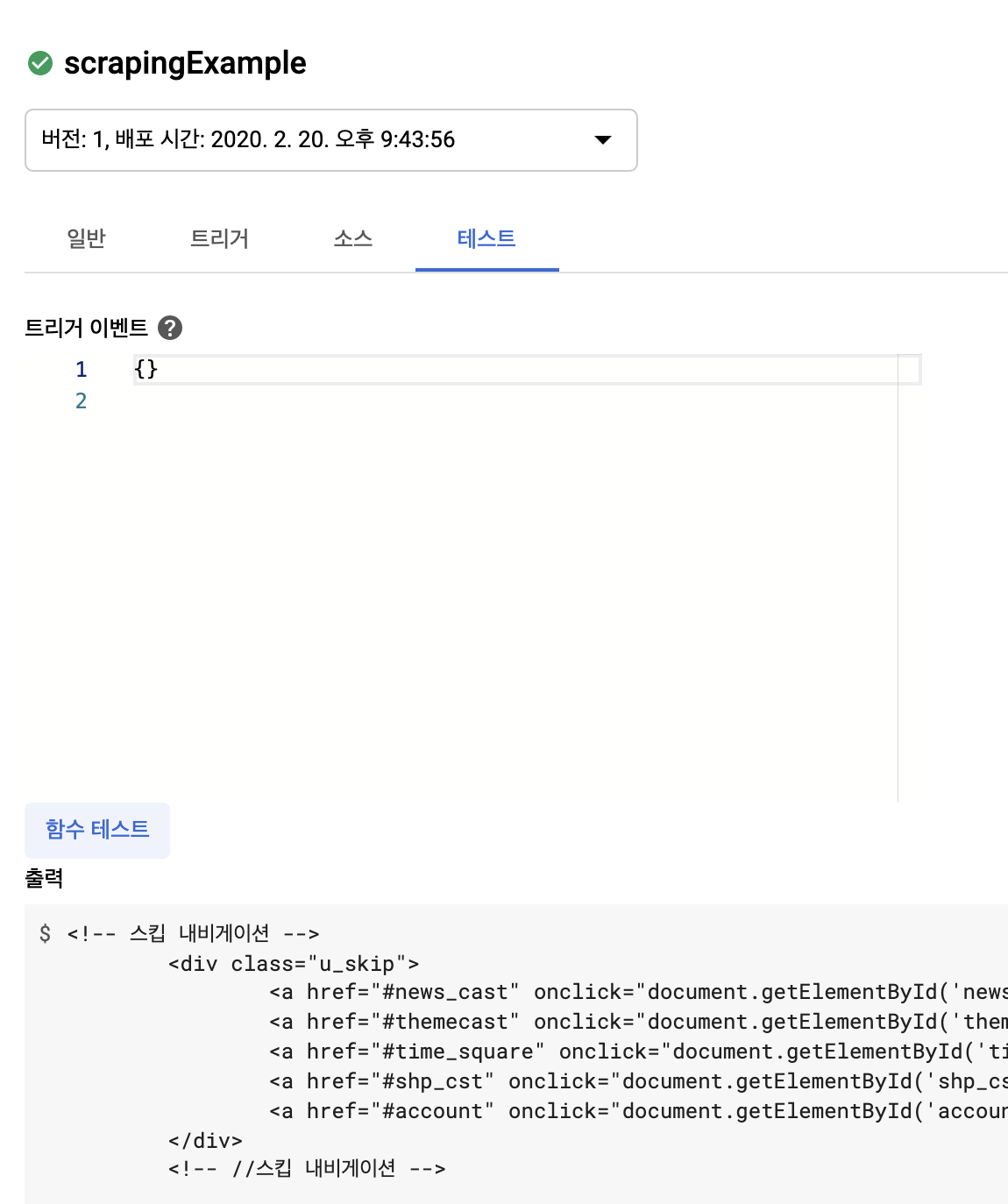
자 그럼 배포한 함수를 주기적으로 크롤링해주기 위해 Google Cloud Scheduler에 등록하도록 하겠습니다.
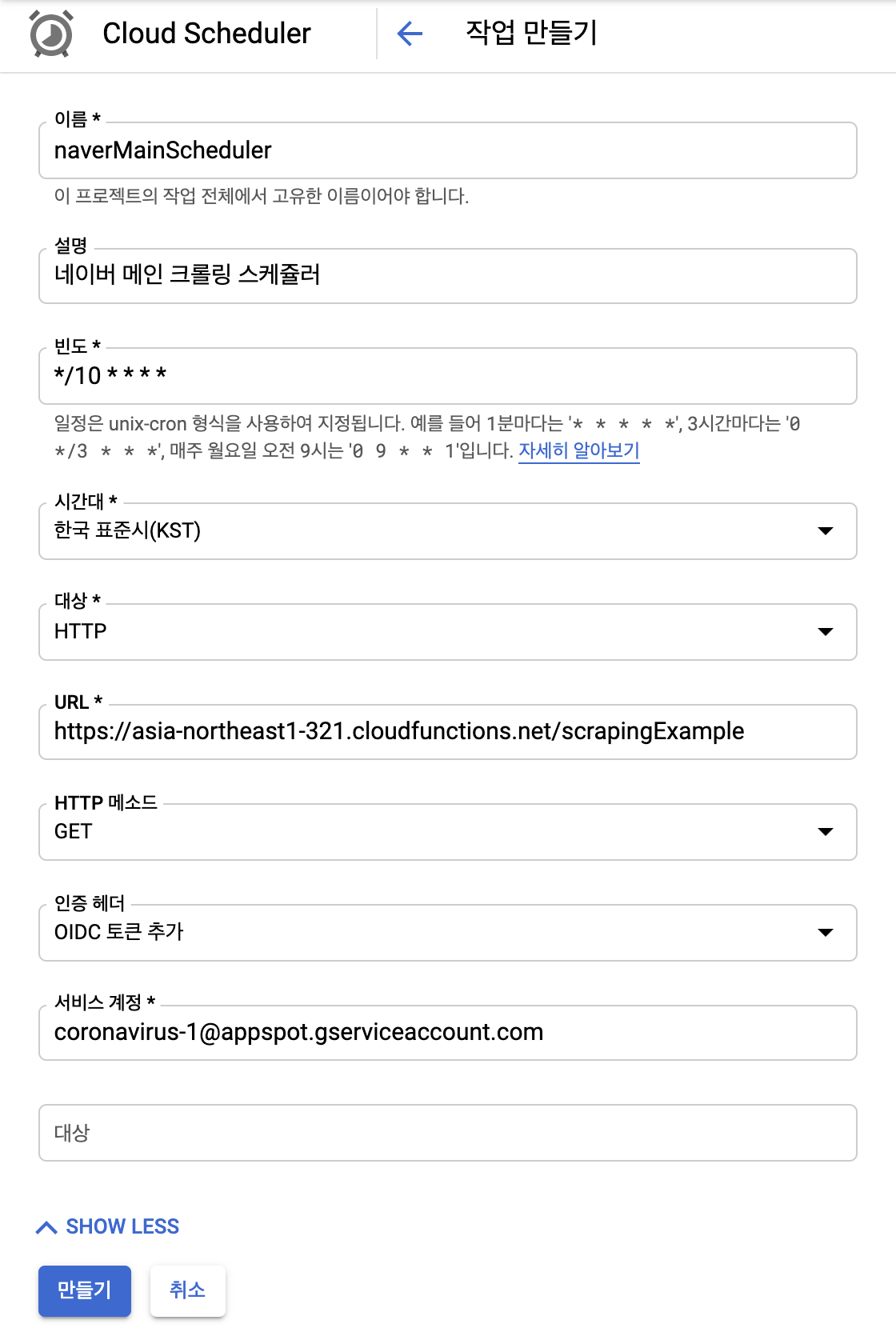
스케줄러를 들어가서 작업 만들기를 누르고 스케줄러에 대한 내용을 작성합니다.
빈도는 크론탭 기준에 맞춰서 작성하시면 됩니다. 저는 10분에 1번(*/10 * * * *) 네이버 메인을 크롤링하는 스케줄러를 생성하겠습니다.
대상은 HTTP 그리고 URL은 좀전에 저희가 배포한 클라우드 함수 경로(함수 상세 정보/트리거 참고) 인증 헤더는 OIDC 토큰 추가, 서비스 계정은 클라우드 함수 하단에 표시되어 있는 서비스 계정을 추가합니다. 자세한 설명은 아래 이미지를 확인하세요.
크론탭을 쉽게 작성하는 방법은 아래를 참고해주세요.
crontab.guru - the cron schedule expression editor
loading... Cron job failures can be disastrous! We created Cronitor because cron itself can't alert you if your jobs fail or never start. Cronitor is easy to integrate and provides you with instant alerts when things go wrong. Learn more about cron job mon
crontab.guru

정상적으로 스케줄러를 등록했습니다. 해당 스케줄러의 우측에 있는 지금 실행을 눌러서 스케줄러를 실행해봅시다.


스케줄러가 정상적으로 실행되었습니다. 그리고 스케줄러가 실행된 시간에 맞춰서 클라우드 함수가 실행되고 클라우드 함수는 네이버 메인을 크롤링한 후 해당 데이터를 storage에 정상적으로 잘 저장되었음을 확인할 수 있습니다.


코드는 아래에서 확인할 수 있습니다.
ruden91/gcf-crawler
구글 클라우드 함수를 활용한 크롤러 예제. Contribute to ruden91/gcf-crawler development by creating an account on GitHub.
github.com
'개발 > Google Cloud Platform' 카테고리의 다른 글
이 포스팅은 쿠팡파트너스 활동의 일환으로, 이에 따른 일정액의 수수료를 제공받습니다.









